I want to announce that I successfully finished my thesis research with an 8. Feel free to read the final version of my report. Thanks for reading!
Colin Schepers - Automatic Decomposition of Continuous Action and State Spaces in Simulation-Based Planning (2012)
Some aditional work (most never intended for distribution):
Colin Schepers - Searching in networks (2010 / Maastricht University / Bachelor Thesis)
Artificial Intelligence for the boardgame Ming Mang (2011 / Maastricht University)
Finding and Lifting a Table Using Two Nao-Bots (2011 / Maastricht University)
NAO Robots lifting a table video (2011 / Maastricht University)
Building a General Game Playing Agent (2011 / Maastricht University)
Mach4 - A BattleCode Player (2011 / Maastricht University)
Blokus3D Solver (2012 / Purpose: Learning C# / WPF)
Wednesday, July 25, 2012
Monday, June 4, 2012
Feedback 04-06-2012
Results

Donut World

- Step limit: 10 steps per episode
- Reward: +1 for being on the donut, 0 otherwise
- Gaussian noise added to the rewards: mean = 0, sigma = 0.5
- Optimal reward equals 7 because of turning the first 3 steps
- Results averaged over 10,000 episodes
- Algorithm MC randomly samples 10-step trajectories and plays the best found
- LTT is the "Level-based Transposition Tree" with first a regression tree discretizing the state space and each leaf of this tree holds a regression tree discretizing the action space (for that region of the state space).
- MTT is the "Mixed Transposition Tree" which is only one regression tree but also splits on the state space.

- Random performs worst, followed by MC.
- Performance wise, STL > RTL and then HOO > IRTI
- LTT performs about average in comparison with the four algorithms mentioned above. MTT performs bad in comparison with the other algorithms (probably due to the problem stated in the previous post), but is still better than MC and Random.

- Obviously MC and Random are the fastest algorithms
- HOO is the slowest and the plot shows its running time of O(n^2)
- TT is a bit slower than RMTL and RSTL, probably due to that fact that they re-use the same tree build in previous real-world steps.
- Initially MTL is a bit faster than STL, but MTL's computational complexity is slightly higher (due to the perfect recall).


Thursday, May 31, 2012
Feedback 31-05-2012
Work
- Presentation last Tuesday went fine. Kurt gave me one tip regarding the Transposition Table; I could mix the state and action space in stead of the level based approach. At a second though this should indeed be better, because splits then can only occur at leafs which means recalling is only done from the leaf to one of the two children (in stead of possibly "rebuilding" a whole new tree structure).
- The so-called Mixed TT is very similar to a regular Regression Tree. In stead of only splitting the action space it can also split the state space. During the selection step the agent chooses the best UCT child in case the node splits the action space and when at a node which splits on the state space the child is chosen according to the current state in the simulation. Each single action updates the tree in stead of a sequence of actions in case of TLS. The tree that is build can again be re-used for later steps.
- I ran an experiment again for the new transposition tree and it comes very close to the best technique RMTL.
- When trying the Mixed TT in combination with HOO (i.e. HOO with state information) I found out this problem: since HOO splits on random dimensions it sometimes occurs that the very first split is on the action space. This means that no matter in which state the agent is in, is will always pick the region of the action space with the best UCT value (which could lead to bad actions if previously the other child was better)? This makes me wonder if the idea behind the Mixed TT is correct and why for regression trees is works so well (probably due to the intelligent splitting which initially splits on the state dimension representing the angle of the pole)?
- Furthermore, not very unimportant (!) I found an small error applicable to the HOO based algorithms. After fixing this and some parameter tuning (raising n_min), I achieved some better results. HOMTL is now reaches 50% succes rate but HOSTL is still computationally too expensive to plan ahead enough steps (the biggest problem is when the cart reaches the left or right "wall", then agent then has to force the pole's angle respectively to the right or left to get away from this wall).
Succes
rate
|
Average
payoff
|
|
RMTL
|
94%
|
971.747
|
RSTL
|
85%
|
922.047
|
HOMTL
|
50%
|
706.525
|
HOSTL
|
5%
|
320.255
|
Level-based TT
|
65%
|
808.480
|
Mixed TT
|
87%
|
924.698
|
MC
|
9%
|
389.590
|
Sunday, May 27, 2012
Feedback 27-05-2012
Work
- Looked into the perfect recall and fixed it. RMTL is able to balance for 1000 steps 94% (vs 69% before). I've updated the table from a couple of posts back and for also provided it below in this post.
- Implemented the transposition tree and works pretty well. For the CartPole environment it performs better than Random, MC, HOMTL and HOSTL (see table). Offline it does not very good and probably lacks information about important states (not provided in the table).
- I removed the number of simulations from the table as in my opinion they were not really comparable anymore since I changed the parameters for HOO so it could achieve more simulations (but less information). Furthermore, the Transposition Tree Agent actually updates the tree structure each step (and not each simulation). Meaning that after 1 rollout, it can actually update 20 times (depending on the length of the rollout). Therefore I chose to remove them out of the table.
- I rerun the noisy Donut World experiment but now with reward noise. I appeared that there is no significant decrease in performance caused by this noise. Furthermore, I tried the transposition tree agent for this environment and it performed better than all other algorithms.
Succes
rate
|
Average
payoff
|
|
IRTI + TLS
|
94%
|
971.747
|
IRTI + HOLOP
|
85%
|
922.047
|
HOO + TLS
|
0%
|
77.254
|
HOO + HOLOP
|
3%
|
273.525
|
Transposition Tree
|
65%
|
808.480
|
MC
|
9%
|
389.590
|
Friday, May 25, 2012
Meeting 25-05-2012
Action Points
- We started with discussing the planning proposed at the beginning of the year. For me, I was pretty accurate, except that I did not yet implement the "transposition tree" and the writing which started a bit later.
- We should use noise for the reward in stead of on the actions because if adding noise to the action can also change the optimal reward function, i.e. even when playing the best actions one would not be able to achieve the best reward. To draw the optimal line when having noisy actions you'd have to calculate products / intervals (to keep it general).
- For multi step results I should also make a MTL-UCT agent
- I asked what to do with the state information of my "transposition tree". Michael proposed an idea and I brainstormed with Andreas afterwards:
- Assume the state/observation space to be Markov
- First level is an "observation tree", discretizing to observation space.
- Each leaf representing a region of this space links to an action tree on the second level, discretizing the action space and keeping information about which actions are best for the observation range from the level above.
- This observation-action tree can be re-used for each state the agent is in due the the property of 1.
- Change last experiment so that noise is on rewards.
- Add the MTL-UCT agent to the experiment
- Look into the global/perfect recall again
- Implement the "transposition tree"
- Writing
Friday, May 18, 2012
Feedback 18-05-2012
Results




I've run the CartPole experiment again with more challenging properties:
[1] H. Van Hasselt and M. A. Wiering, “Reinforcement learning in continuous action spaces,” in Approximate Dynamic Programming and Reinforcement Learning 2007 ADPRL 2007 IEEE International Symposium on, no. Adprl, pp. 272–279, 2007.
Sinus environment: time-based


Six Hump Camel Back environment: time-based


CartPole environment: time-based
I've run the CartPole experiment again with more challenging properties:
- Goal: balance the pole for 1000 steps
- Payoff:
- For each step that the pole is balanced: +1
- If the pole's angle is > 12 degrees from upright position: -1 (and terminal state)
- Maximum expected payoff of 1000 due to the goal's statement
- Added Gaussian noise with standard deviation of 0.3 to both rewards and actions
- See [1] for more detailed description of the environment properties
- Agent's evaluation time per step: 50 ms
Succes
rate
|
Average
payoff
|
|
IRTI + TLS
|
94%
|
971.747
|
IRTI + HOLOP
|
85%
|
922.047
|
HOO + TLS
|
0%
|
77.254
|
HOO + HOLOP
|
3%
|
273.525
|
Transposition Tree
|
65%
|
808.480
|
MC
|
9%
|
389.590
|
[1] H. Van Hasselt and M. A. Wiering, “Reinforcement learning in continuous action spaces,” in Approximate Dynamic Programming and Reinforcement Learning 2007 ADPRL 2007 IEEE International Symposium on, no. Adprl, pp. 272–279, 2007.
Wednesday, May 16, 2012
Feedback 16-05-2012
Work
Below is my planning from my last post with comments.
Below is my planning from my last post with comments.
- Investigate why the IRTI line horizontal at the end of the Six Hump Camel Back Experiments.
- The maximum tree depth was not the cause
- It was caused due to the fact that the values get really close together at some point and the exploration value is not able to "fix" random bad choices (at least not within a reasonable number of sampels)
- Implement a visualization to show at which time a split occurs (at which sample number).
- See the two posts with the results of the Sinus and Six Hump Camel Back environment
- The "1-dimensional heatmap" or "vector or colors" representation did not look so nice as the graph representation
- Check if it is correct that the RMTL agent has a significant decrease in number of simulations per second when memorization is enabled, as seen in the table of the last post.
- This is correct
- Think which parameters are relevant (to mention in the report) and remove the redundant.
- The posts with the Sinus and Six Hump results are edited and now only show a reduced amount of relevent parameters
- Optimize the multi-step agents
- Been tweaking the multi-step agents a lot
- Think of a graph representation of the multi-step experiments and rerun them under more difficult settings, i.e. less time or the settings from the paper (with noisy rewards, noisy actions, etc).
- I tried a different setting for the CartPole which is a bit more difficult [1]
- I found out that Vanilla MC is really good and outperforms all the other algorithms; it can balance perfectly each time given only 50ms per step. The reason is because it can achieve a high number of simulations.
- I saw that for greedy pick I used the best sample found and not the best sample of the leaf with the best mean (for the results of the post from 02-05). In the first case, the agent is comparible with the Vanilla agent and performs pretty well while in the latter case, the agent performs worse and is not able to achieve enough simulations for an accurate approximation.
- The Donut World environment has the property/flaw that optimizing (only) the next step is sufficient and no future planning is actually needed.
- Implement perfect recall on meta tree level
- Implemented a way that multi-step action sequences with reward sequences are stored and "replayed" whenever a split occurres, as discussed with Lukas and Andreas. It seems the agents perform better with this option.
- Furthermore, I've been writing on the report.
- Report writing
- Work on multi-step agents and experiments
- Implement Transposition Tree
[1] H. Van Hasseld and M.A. Wiering, "Using Continuous Action Spaces to Solve Discrete Problems".
Wednesday, May 2, 2012
Meeting 02-05-2012
Discussion Points
Andreas, Lukas and me presented the results of the experiments (see previous posts for my results). I've got some usefull feedback and comment, which are summarized in the planning below.
Planning
Andreas, Lukas and me presented the results of the experiments (see previous posts for my results). I've got some usefull feedback and comment, which are summarized in the planning below.
Planning
- Investigate why the IRTI line horizontal at the end of the Six Hump Camel Back Experiments.
- Implement a visualization to show at which time a split occurs (at which sample number).
- Check if it is correct that the RMTL agent has a significant decrease in number of simulations per second when memorization is enabled, as seen in the table of the last post.
- Think which parameters are relevant (to mention in the report) and remove the redundant.
- Optimize the multi-step agents
- Think of a graph representation of the multi-step experiments and rerun them under more difficult settings, i.e. less time or the settings from the paper (with noisy rewards, noisy actions, etc).
- Implement perfect recall on meta tree level
- Implement Transposition Tree
Feedback 02-05-2012
Multi-step Results
I've ran some experiments regarding the four multi-step algorithms in the CartPole environment:
- I used pretty "easy" settings for the environment (no transition/reward/observation noise, a small but sufficient action space (force applied to the cart), etc.).
- On the other hand, I limited the agent to (only) 100 ms per step.
- The rewards are equal to the number of steps the agent is able to balance the pole.
- Per algorithm, 100 runs were performed.
- Note that I did not improve/profile the agents yet and neither did I tune the parameters in detail. Furthermore, I could only do 100 runs due to time constraints of today's meeting. Therefore, the results have to be considered preliminary.
- The next table shows the number of simulations each algorithm can perform in 1 second (roughly; on average) during the first 10 steps in the CartPole environment.
Thesis Overview

I've ran some experiments regarding the four multi-step algorithms in the CartPole environment:
- I used pretty "easy" settings for the environment (no transition/reward/observation noise, a small but sufficient action space (force applied to the cart), etc.).
- On the other hand, I limited the agent to (only) 100 ms per step.
- The rewards are equal to the number of steps the agent is able to balance the pole.
- Per algorithm, 100 runs were performed.
- Note that I did not improve/profile the agents yet and neither did I tune the parameters in detail. Furthermore, I could only do 100 runs due to time constraints of today's meeting. Therefore, the results have to be considered preliminary.
algorithm | reward
|
<= 100
|
> 100
|
> 250
|
> 500
|
>= 1000
|
RMTL
|
0
|
0
|
0
|
1
|
99
|
RSTL
|
2
|
2
|
3
|
3
|
90
|
HOSTL
|
2
|
2
|
3
|
8
|
85
|
HOMTL
|
0
|
0
|
0
|
0
|
100
|
- The next table shows the number of simulations each algorithm can perform in 1 second (roughly; on average) during the first 10 steps in the CartPole environment.
algorithm | avg sims/s
|
Memorization
|
No memorization
|
RMTL
|
37000
|
39000
|
RSTL
|
18000
|
32000
|
HOSTL
|
7300
|
7700
|
HOMTL
|
5000
|
5000
|
Thesis Overview

Friday, April 27, 2012
Feedback 27-04-2012
Experiment Results
I also ran experiments in the Six Hump Camel Back environment. Again, all experiments are done over 1000 samples and are averaged over 1000 runs. For every experiment the 95% confidence intervals are displayed by a colored region surrounding the lines.
Incremental Regression Tree Induction (IRTI)
- MCTS_C = (parentRangeSize / globalRewardVolume) * Config.MCTS_K
- MCTS_K=1.0
- IRTI_SPLIT_NR_TESTS=100
- IRTI_SPLIT_MIN_NR_SAMPLES=75
- IRTI_SIGNIFICANCE_LEVEL=0.001
- IRTI_MEMORIZATION = true








Hierarchical Optimistic Optimization (HOO)
- MCTS_C = (parentActionSpaceVolume / globalActionSpaceVolume) * globalRewardVolume * MCTS_K)
- MCTS_K=0.5
- HOO_V_1 = (sqrt(nrActionDimensions) / 2) ^ HOO_ALPHA
- HOO_RHO = 2 ^ (- HOO_ALPHA / nrActionDimensions)
- HOO_ALPHA=0.99
- HOO_MEMORIZATION = true








IRTI + HOO + MC + Random + UCT (pre-discretization with 2 splits per depth)



Planning
- Run experiments regarding the multi-step agents and possibly debug / optimize code.
Sunday, April 22, 2012
Feedback 22-04-2012
Experiment Results
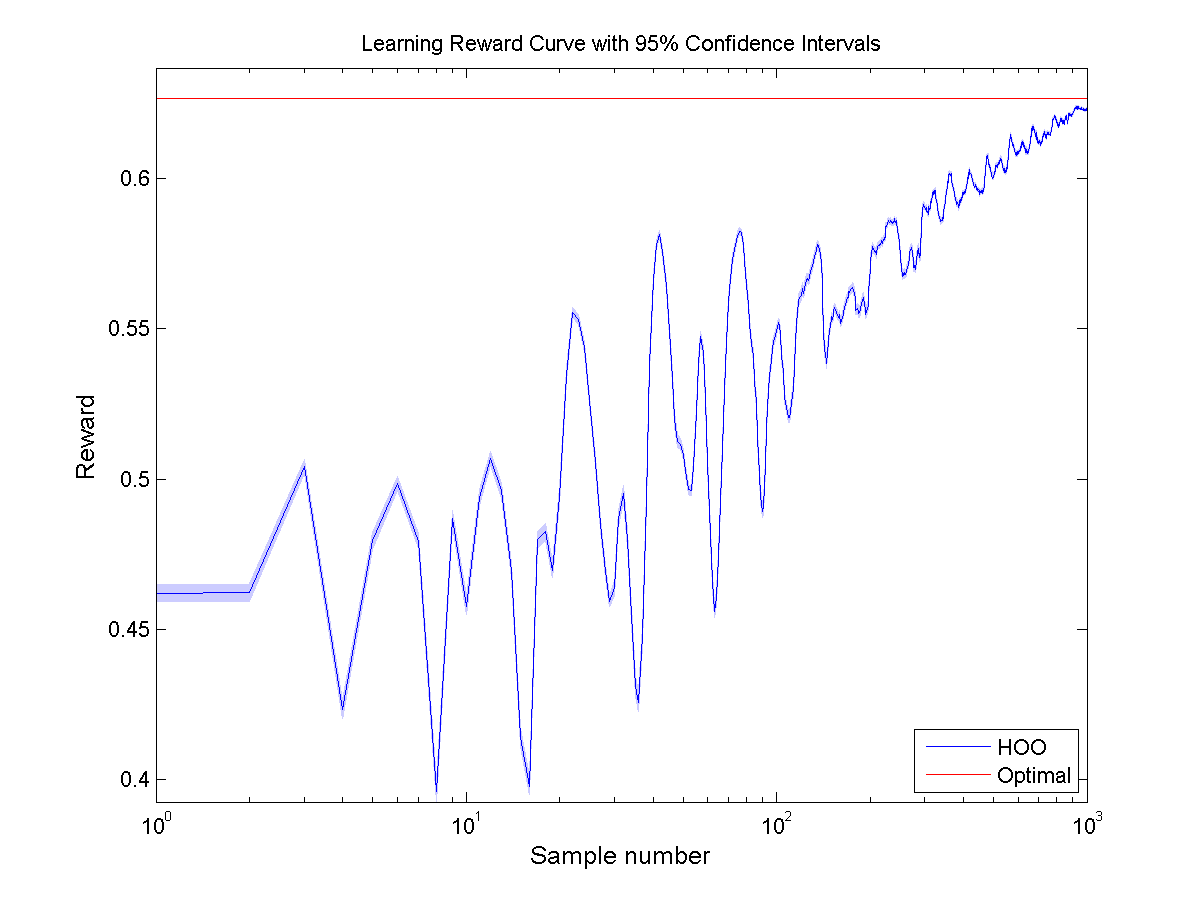
Finally some nice results to show after some debugging and parameter tuning; manual and automatic. All experiments are done over 1,000 samples and are averaged over 10,000 runs. For every experiment the 95% confidence intervals are displayed by a colored region surrounding the lines.











.png)
.png)
.png)
.png)




Work
Implemented all four multi-step agents and seem to be able to balance the pole in the Cartpole environment pretty well.
Incremental Regression Tree Induction (IRTI)
- MCTS_C = (childRewardRangeSize / globalRewardRangeSize) * MCTS_K)
- MCTS_K = 2.0
- IRTI_SPLIT_NR_TESTS = 100
- IRTI_SPLIT_MIN_NR_SAMPLES = 50
- IRTI_SIGNIFICANCE_LEVEL = 0.001
- IRTI_MEMORIZATION = true





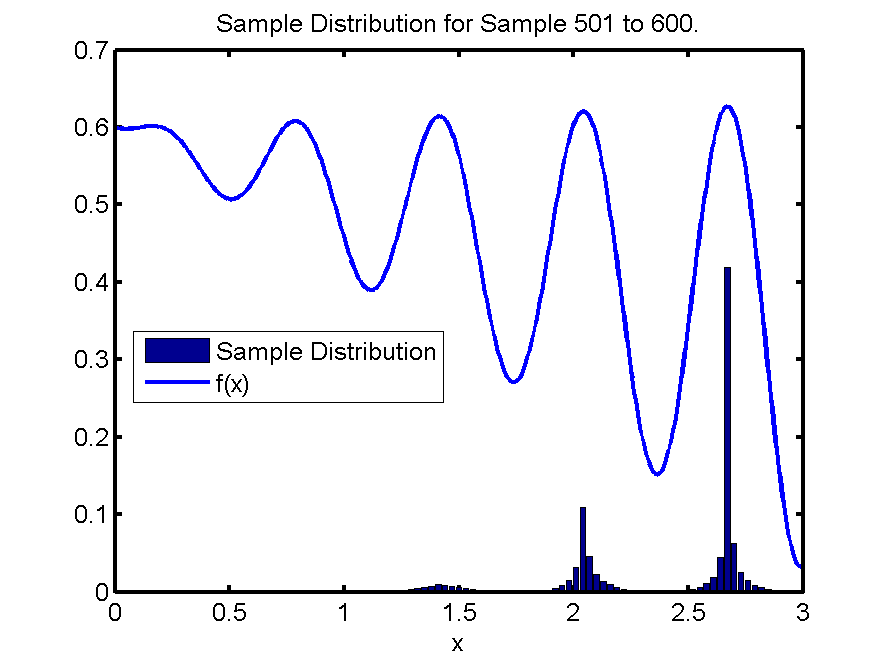


Hierarchical Optimistic Optimization (HOO)
- MCTS_C = (parentActionSpaceVolume / globalActionSpaceVolume) * globalRewardVolume * MCTS_K
- MCTS_K=5.0
- HOO_MEMORIZATION = true
- HOO_V_1 = (sqrt(nrActionDimensions) / 2) ^ HOO_ALPHA
- HOO_RHO = 2 ^ (- HOO_ALPHA / nrActionDimensions)
- HOO_ALPHA = 0.99


.png)
.png)
.png)
.png)

IRTI + HOO + MC + Random + UCT (pre-discretization with 25 splits per depth)



Work
- Regression-based Meta Tree Learning agent (RMTL)
- Hierarchical Optimistic Meta Tree Learning agent (HOMTL)
- Regression-based Sequence Tree Learning agent (RSTL)
- Hierarchical Optimistic Sequence Tree Learning agent (HOSTL)
- Find a better parameter set for HOO for the Six Hump Camel Back function as it is now barely better than UCT with pre-discretization in that environment. I can then generate the same pictures as the ones above.
- Do experiments regarding the multi-step agents and possibly debug / optimize code.
Saturday, April 14, 2012
Meeting 12-04-2012
Work
- Fixing, debugging and improving IRTI and HOO.
- Furthermore, a lot of parameter tuning for above two algorithms.
- Michael and I had a discussion about the exploration factor
- C should be related to the reward range
- constant C = globalRangeSize * K
- adaptive C = parentRangeSize * K
- Lukas proposed: adaptive C = (childRangeSize / globalRangeSize) * K
- For HOO, you should also multiply the last term (diam) with C or divide the first term (mean reward) with C.
- R + C * exploration + C * diam
- R / C + exploration + diam
Planning
- Change the HOO formula (see action points)
- Generate reward distributions (learning curve, greedy curve, error) of several algorithms
- IRTI
- HOO
- UCT (pre-discretization)
- Vanilla MC (random sampling, greedy returns best sample seen)
- Random
- I should ask Lukas about the working of his IRTI algorithm to find out why mine does not converge samling at the global maximum.
Subscribe to:
Posts (Atom)