Experiment Results
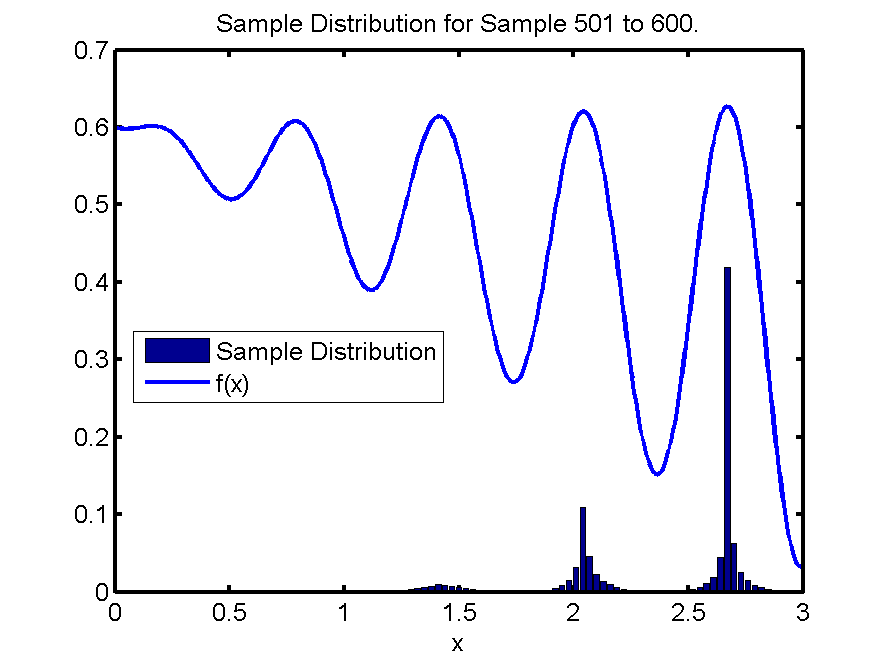
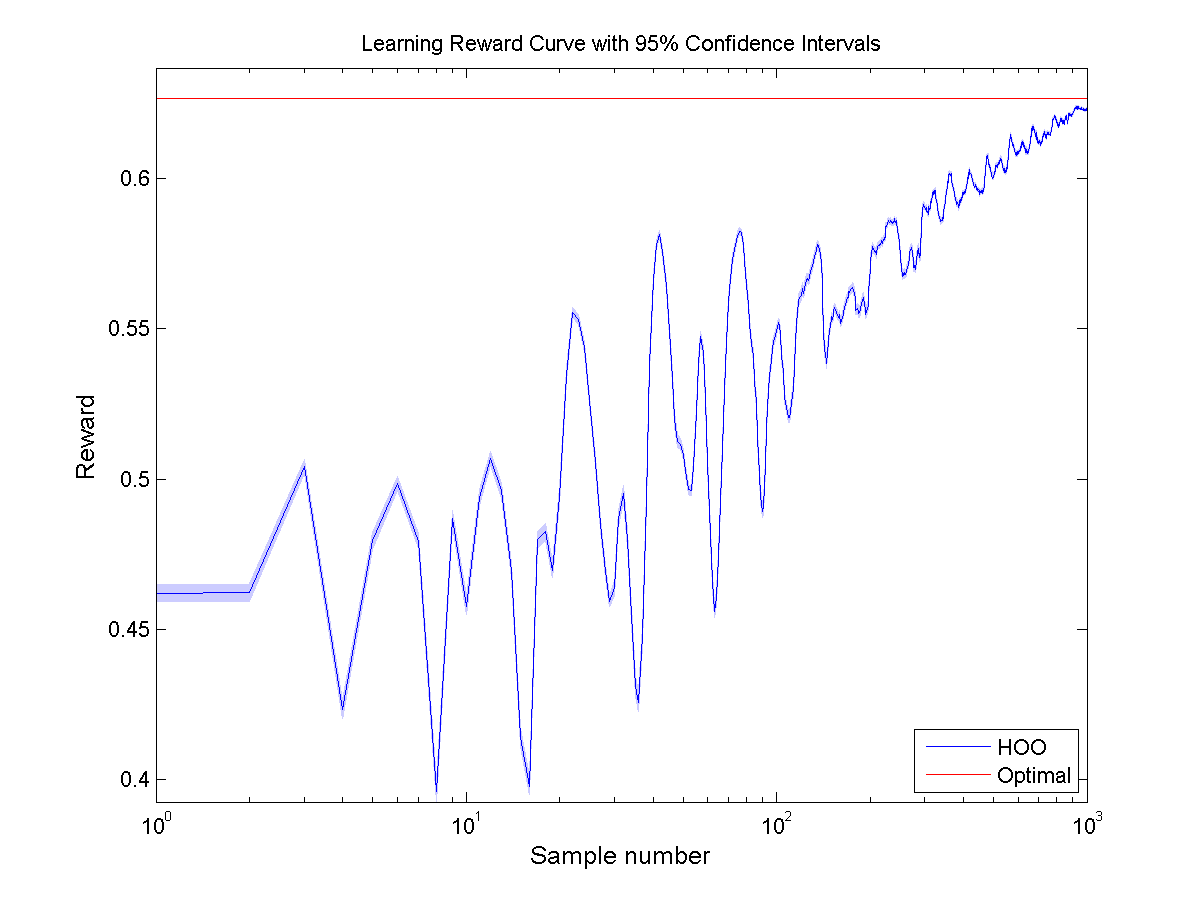
I also ran experiments in the Six Hump Camel Back environment. Again, all experiments are done over 1000 samples and are averaged over 1000 runs. For every experiment the 95% confidence intervals are displayed by a colored region surrounding the lines.
Incremental Regression Tree Induction (IRTI)
- MCTS_C = (parentRangeSize / globalRewardVolume) * Config.MCTS_K
- MCTS_K=1.0
- IRTI_SPLIT_NR_TESTS=100
- IRTI_SPLIT_MIN_NR_SAMPLES=75
- IRTI_SIGNIFICANCE_LEVEL=0.001
- IRTI_MEMORIZATION = true








Hierarchical Optimistic Optimization (HOO)
- MCTS_C = (parentActionSpaceVolume / globalActionSpaceVolume) * globalRewardVolume * MCTS_K)
- MCTS_K=0.5
- HOO_V_1 = (sqrt(nrActionDimensions) / 2) ^ HOO_ALPHA
- HOO_RHO = 2 ^ (- HOO_ALPHA / nrActionDimensions)
- HOO_ALPHA=0.99
- HOO_MEMORIZATION = true








IRTI + HOO + MC + Random + UCT (pre-discretization with 2 splits per depth)



Planning
- Run experiments regarding the multi-step agents and possibly debug / optimize code.









.png)
.png)
.png)
.png)















